Today, on 9 June 2026, Anthropic released Claude Fable 5 – the first publicly available model of the so-called Mythos class, the model family that gave the cybersecurity world a considerable fright back in April. The headlines celebrate the capability jump: state-of-the-art scores on nearly every benchmark, a coding model that completed a migration across 50 million lines of Ruby code in a single day. Impressive. But the genuinely interesting story is not in the benchmark table. It is in the architecture of the release.
Anthropic has turned a single model into two products. Fable 5 is the public variant, wrapped in classifiers. Mythos 5 is the same model with its cyber safeguards lifted, available only to selected Project Glasswing partners and the US government. Both cost the same. What separates them is not capability but access. And that dividing line is the story a banker should be reading.
What: on 9 June 2026 Anthropic releases Claude Fable 5 (public, with safeguards) and Claude Mythos 5 (the same model, cyber safeguards lifted, restricted to Glasswing partners)
Performance: Fable 5 / Mythos 5 leads nearly every published benchmark – SWE-Bench Pro 80.3% vs 69.2% for Opus 4.8, knowledge work GDPval-AA 1932 vs 1890
Safeguards: queries on cybersecurity, biology/chemistry and distillation are routed back to the older Opus 4.8; triggered in fewer than 5% of sessions, and users are informed
Price: USD 10 per million input tokens, USD 50 per million output tokens – twice the rate of Opus 4.8 (USD 5/25)
Data: mandatory 30-day retention for all Mythos-class traffic, including via third parties; overrides existing zero-data-retention arrangements, with no training on this data
One model, two products – and a deliberate wall
The benchmark numbers themselves are real and well documented. Anthropic's official comparison table places Fable 5 clearly ahead of Claude Opus 4.8, GPT-5.5 and Gemini 3.1 Pro on agentic coding, knowledge work, spatial reasoning, legal tasks and health.
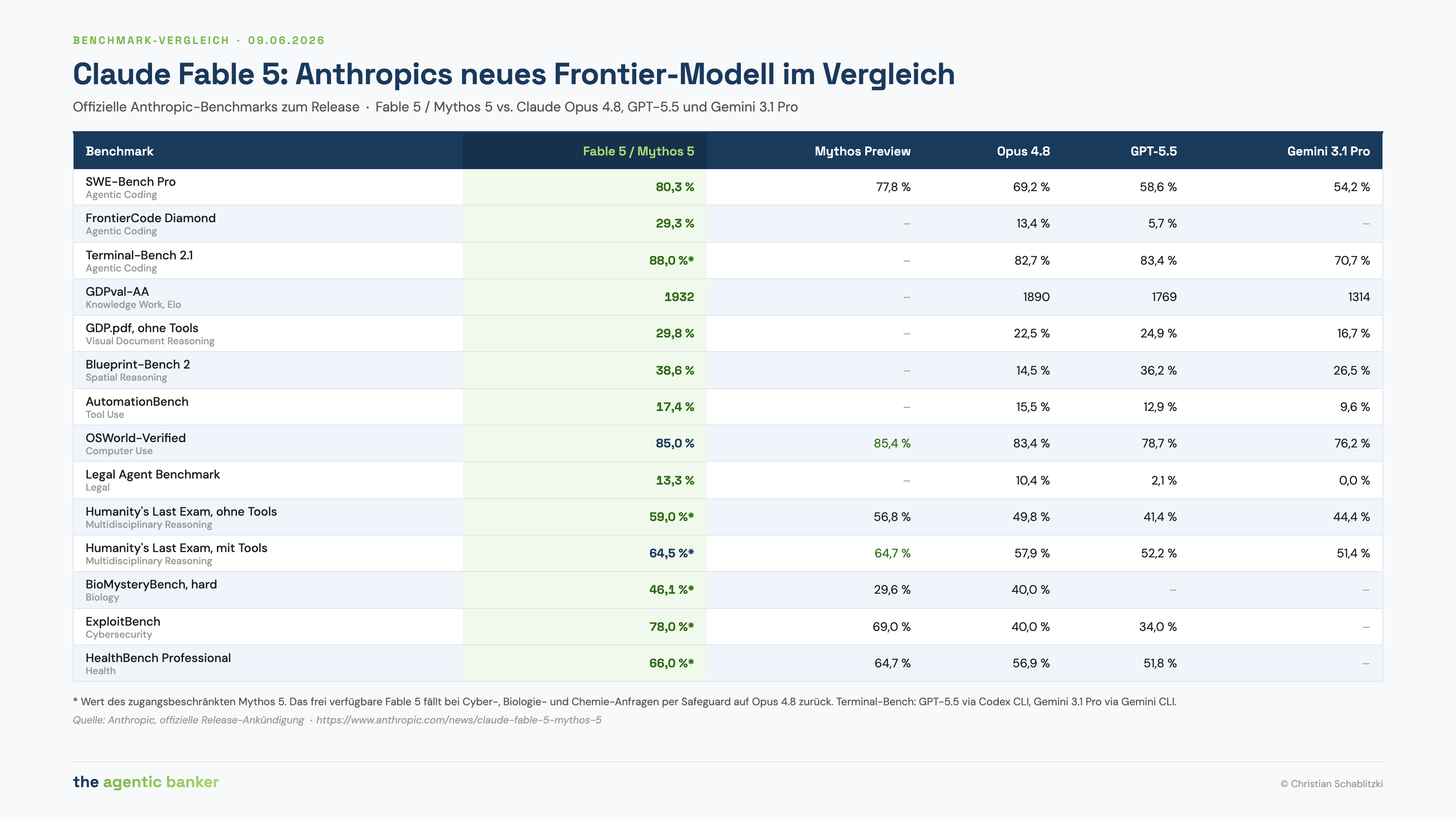
Here is the first qualification that most coverage misses. Several of the most spectacular figures carry an asterisk. ExploitBench, the cybersecurity benchmark, shows 78.0% – but that is the score of Mythos 5, the model behind the wall. The freely available Fable 5 makes zero per cent progress on offensive cyber tasks in blocking mode, because those exact queries are routed to Opus 4.8, which scores 40% there. Anyone who lifts headline Fable 5 figures from the cyber or biology rows into a compliance, risk or procurement document is citing the performance of a model they cannot actually deploy.
Frontier capability is now rationed by trust, not by price
This is the real break. Until now the logic of the frontier labs was simple: the best model is open to anyone who pays the list price. By splitting the model into Fable and Mythos, Anthropic has abandoned that logic. The strongest cyber capability in the world – Anthropic's own characterisation – is not distributed by price but by a trust assessment. Those on the Glasswing list get it. Those who are not get a model that shifts down a gear on precisely those questions.
The irony is tangible. In April, Mythos autonomously found thousands of zero-day vulnerabilities, and the UK AI Security Institute confirmed capabilities beyond most elite human researchers. That very capacity for autonomous vulnerability detection would be an enormous lever for a bank's defence. And it is no coincidence that JPMorganChase is among the founding Glasswing partners, or that US Treasury Secretary Scott Bessent, together with Fed Chair Jerome Powell, encouraged large banks to test the model in April. The question of who gets access to the strongest defensive AI capability has thus moved out of the market and into the product architecture of a private vendor.
Three questions that now belong on the table
For CISOs, CROs and procurement leads at financial institutions, this release shifts three very concrete issues – regardless of whether their own organisation deploys Fable 5 tomorrow.
The benchmark number in the board paper and the performance that actually lands in production can diverge for Fable 5 in regulation-adjacent domains. Model risk management here means checking whether the cited metric applies to the model you can really deploy, not to its access-restricted sibling.
Anthropic requires 30-day data retention for all Mythos-class traffic, including via third parties such as GitHub Copilot, and in doing so overrides previously negotiated zero-data-retention commitments. For a DORA-regulated institution this is not fine print but a matter of data governance and contractual outsourcing architecture.
The Financial Stability Board and the BIS have named dependence on a few dominant AI providers as a leading financial-stability vulnerability for over a year. A model whose highest capability tier reaches only a hand-picked partner list turns that abstract warning into a very concrete question of negotiating power and dependency.
The gating is defensible
I want to take the counterposition seriously, because it is strong. A freely available model with unrestrained offensive cyber capability would be a gift to attackers. Anthropic's decision to put the most dangerous capabilities behind a trust assessment and to fall back to the weaker Opus 4.8 in the public model is a reasonable, and probably correct, way of handling a real dual-use danger. The safeguards intervene in fewer than five per cent of sessions, the user is informed, and through Project Glasswing banks do get full access after all – just curated. Anyone calling for an open frontier cyber model for everyone should know very precisely who else they would be handing it to.
And yet the uncomfortable remainder stays. A private company now decides, by product design, who gets access to the strongest defensive capability – a decision with a distinctly public character. European supervision, in the systemic-risk tier of the AI Act, still thinks in terms of one model, one risk profile. A model that becomes a different model depending on the type of query and the access tier fits that grid only with difficulty.
The dividing line remains
What I will be watching most closely in the coming months is not the next benchmark record. It is whether the two-class distribution of AI capability becomes a pattern – and whether supervision and procurement find an answer to it that goes beyond one model, one datasheet. Fable 5 is an impressive tool. But the story of the day is the wall, not the model behind it.

Christian Schablitzki
Strategy & Management Consultant · Agentic AI expert for financial institutions
Over 20 years in investment banking and derivatives trading, followed by more than 10 years advising financial institutions. Currently a Partner at Infosys Consulting in Germany. Certified in Google AI, Generative AI Leader (Google Cloud) and IBM RAG and Agentic AI.
LinkedIn profile →Keep reading – every two weeks in your inbox.
Capital markets insights, regulatory updates and AI trends. Concise, well-founded, free.
GDPR-compliant. Unsubscribe anytime.